AIOps für KMU: Störungen schneller erkennen und mit Incident Automatisierung automatisch beheben
Geschätzte Lesezeit: 15 Minuten
Key Takeaways
- AIOps reduziert MTTR und MTTD deutlich durch KI-gestütztes Monitoring und Event-Korrelation.
- Automatisierte Incident-Workflows entlasten kleine IT-Teams und sorgen für schnellere Wiederherstellung.
- Start mit einem klar definierten Pilot (1–2 Services) — messen, beweisen, dann skalieren.
- Sicherheit und Governance sind entscheidend: Audit-Logs, RBAC und Approval-Gates verhindern Nebenwirkungen.
- Praktische Playbooks und eine 30-Minuten-Mini-Audit-Vorlage machen den Einstieg direkt umsetzbar.
Inhaltsverzeichnis
- Einführung
- Warum AIOps für KMU heute so relevant ist
- Die wichtigsten KPIs und wie du sie berechnest
- Kernkomponenten von AIOps
- Technische Architektur und Integrationen
- ML-Modelle und Feature-Engineering
- Schritt-für-Schritt Roadmap
- Konkrete Playbooks
- Risiken und Fallstricke
- Sicherheit, Compliance und Governance
- Rollen und Change Management
- Tools und Anbieter auswählen
- Erfolgsbeispiele
- Dein 30-Minuten-Mini-Audit
- Fazit
- FAQ
Einführung
AIOps für KMU verändert, wie kleine und mittelständische Unternehmen Störungen erkennen und beheben.
Wo früher ein IT-Mitarbeiter stundenlang Logs durchsuchen musste, übernimmt heute künstliche Intelligenz die Erstanalyse — und das in Sekunden.
Mit KI-gestütztem Monitoring, Event-Korrelation und Auto-Remediation lassen sich MTTR deutlich reduzieren und die Betriebsstabilität spürbar erhöhen.
AIOps (Artificial Intelligence for IT Operations) kombiniert Big-Data-Plattformen, Machine-Learning-Modelle und Automatisierung, um Monitoring-Daten zu korrelieren, Ursachen schneller zu identifizieren und Remediation-Schritte automatisch auszuführen.
Kurz gesagt: Das System erkennt Probleme früher, ordnet sie richtig ein und löst viele davon selbst — ohne dass jemand um 3 Uhr nachts aufwachen muss.
Dieser Leitfaden ist praxisorientiert. Du bekommst eine klare Roadmap, Checklisten für Pilot und Produktion, konkrete Playbooks und messbare KPIs. Alles so aufgebaut, dass du direkt loslegen kannst.
Weiterführende Lektüre: HPE AIOps-Blog, IT‑Schulungen – AIOps Überblick, Mittelstandswiki – AIOps.
Warum AIOps für KMU heute so relevant ist
Viele KMU kämpfen täglich mit denselben drei Problemen. Erstens: zu wenig IT-Personal. Zweitens: gewachsene, heterogene IT‑Landschaften. Drittens: manuelle Incident‑Response kostet Zeit und Geld.
Die Folgen sind konkret spürbar: lange MTTR bedeutet längere Ausfallzeiten für Kunden; Alert‑Fatigue lässt Teams Alarme ignorieren; und Ausfallkosten können für Onlinehändler schnell fünfstellige Summen pro Stunde erreichen.
Methoden zur Reduktion von Alert‑Fatigue findest du hier: Alert‑Fatigue reduzieren.
AIOps für KMU löst genau diese Probleme: KI‑gestütztes Monitoring erkennt Anomalien früher, Automatisierung übernimmt Routineaufgaben und Überwachung skaliert mit der Infrastruktur — ohne zusätzliches Personal.
Business‑Vorteile im Überblick:
- Schnellere Erkennung: KI findet Abweichungen oft Minuten oder Stunden vor Ausfall.
- Weniger manuelle Arbeit: Ticket‑Erstellung, erste Diagnose und einfache Fixes laufen automatisch.
- Geringere Personalkosten: Team fokussiert auf komplexe Probleme.
- Skalierbare Überwachung: Neue Services integrieren sich leichter.
- Messbare KPIs: MTTR und MTTD sind leicht nachvollziehbare Kennzahlen für die Geschäftsführung.
Quellen: HPE AIOps, Mittelstandswiki, IT‑Schulungen.
Die wichtigsten KPIs und wie du sie berechnest
Bevor du mit AIOps startest, brauchst du eine Baseline. Nur wenn du weißt, wo du heute stehst, kannst du später Verbesserungen nachweisen.
MTTR (Mean Time To Repair): Durchschnittliche Zeit von Entstehung bis Wiederherstellung.
Formel: MTTR = Summe der Dauer aller Incidents ÷ Anzahl der Incidents.
MTTD (Mean Time To Detect): Zeit bis zur Erkennung eines Incidents. KI‑Monitoring reduziert diese Zeit signifikant.
Auto‑Remediation‑Rate: automatisch gelöste Incidents ÷ Gesamtanzahl × 100. Ziel im Pilot: 20–30 %.
Weitere Metriken: Alert‑Reduktion (%), False‑Positive‑Rate, Eingesparte Stunden (FTE × eingesparte Stunden).
Messrhythmus: tägliche Dashboards, wöchentliche KPI‑Reviews, quartalsweise Executive‑Summary.
Quellen: IT‑Schulungen, Mittelstandswiki.
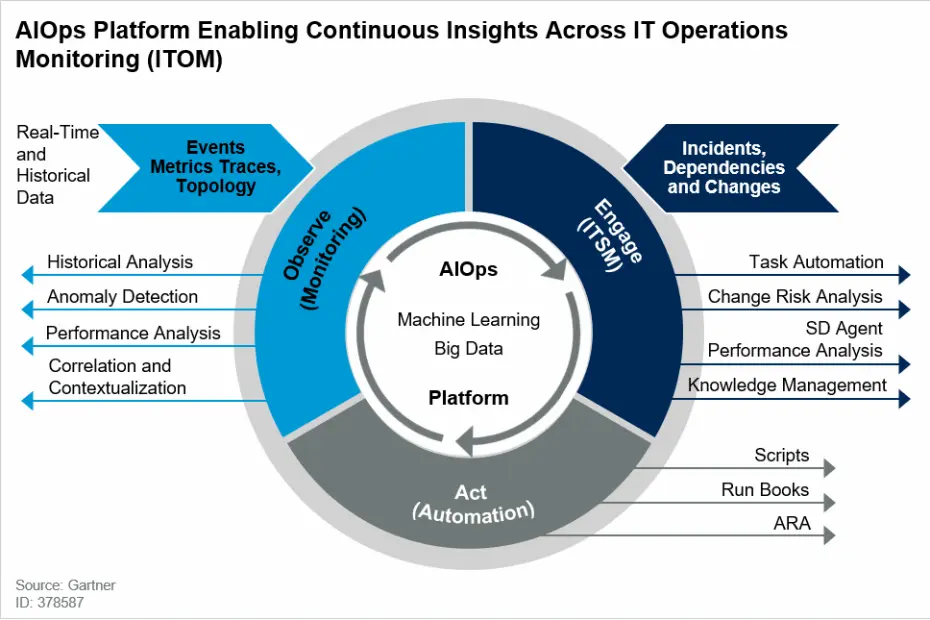
Kernkomponenten von AIOps: Was steckt dahinter?
KI-gestütztes Monitoring: Früher sehen, bevor es brennt
Kontinuierliche Erfassung von Logs, Metriken und Traces kombiniert mit ML‑Algorithmen zur Früherkennung. Denk an Adaptive Thresholds, Seasonality‑aware Baselines, Anomaly Scoring und Alert Enrichment.
Mindestanforderung: mindestens 90 Tage historische Logs und strukturierte Tags (Service, Environment, Host). Drei Schritte zum Setup:
- Daten anbinden (z. B. Fluentd, Prometheus).
- Baseline trainieren (30–90 Tage).
- Tuning und Feedback‑Loop (false positives markieren).
Weiterführend: IT‑Schulungen, KMUit Glossar, Observability für KMU.
Event Korrelation: Aus hundert Alarmen einen machen
Event Korrelation gruppiert hunderte Alerts zu wenigen, aussagekräftigen Events und zeigt den wahrscheinlichen Root Cause. Techniken: Clustering, Topology‑aware Correlation, Temporal Correlation.
Typischer Flow: Alerts → Duplikate entfernen → Korrelations‑Engine → Incident mit Root Cause → ITSM‑Integration (z. B. ServiceNow oder Jira).
Quellen: IT‑Schulungen, KMUit.
Incident Automatisierung: Kein Ticket mehr von Hand anlegen
Automatische Erstellung, Klassifizierung, Priorisierung und Orchestrierung von Incidents in der ITSM‑ und DevOps‑Toolchain.
Beispiele: Auto‑Ticketing, Intelligent Routing, Automated Diagnostics.
Ablauf: Alert → Runbook auswählen → Vorprüfungen → Playbook ausführen (optional manueller Freigabe‑Schritt) → Ticket aktualisieren.
Mehr dazu: IT‑Schulungen, OpenText – AI Operations Management.
Auto‑Remediation: Probleme lösen, bevor jemand aufwacht
Sichere, automatisierte Gegenmaßnahmen per Skripten oder Orchestrations‑Playbooks. Typische Aktionen: Service‑Restart, automatische Skalierung, Config‑Rollback, Cleanup‑Tasks.
Sicherheitsmechanismen: idempotente Aktionen, Dry‑Run, Approval Gates, automatisches Rollback, Audit‑Logging, RBAC.
Quellverweise: IT‑Schulungen, OpenText, Patch Management, Sicherheitsautomatisierung.
Technische Architektur und Integrationen
Eine AIOps‑Plattform besteht aus Data Layer, Ingest & Storage, Processing & ML, Orchestration & Automation sowie UI & Observability.
Wichtige Komponenten:
- Data Layer: Fluentd, Logstash, Prometheus, Jaeger/Zipkin, CMDB.
- Ingest & Storage: Kafka, Time‑Series DB, Object Storage, Elasticsearch.
- Processing & ML: Feature Store, MLflow, Kubernetes.
- Orchestration & Automation: StackStorm, Ansible Tower, Rundeck; ITSM‑Connector.
- UI & Observability: Dashboards, Incident Console, Audit‑Logs.
Anforderungen: Alerts < 3 Minuten Erkennungszeit, Logs ≥ 90 Tage Retention, Verschlüsselung in Ruhe und Übertragung. Backup und DR: Backup‑Leitfaden, Disaster Recovery.
Quellen: IT‑Schulungen, KMUit, OpenText.
ML‑Modelle und Feature‑Engineering: Was wirklich hinter der KI steckt
Modelltypen:
- Anomalie‑Erkennung (unsupervised): Isolation Forest, Autoencoder.
- Klassifikation (supervised): Random Forest, XGBoost (benötigt gelabelte Historie).
- Graph‑basierte Root‑Cause‑Modelle für Abhängigkeitsanalysen.
- Predictive Maintenance: Prophet, LSTM.
Features: CPU, Memory, I/O‑Latenz, Fehlerraten, Requests/s, Deployment‑Flags, Konfig‑Änderungen.
Pipeline: Sliding Windows (5/15/60 min), Interpolation fehlender Werte, Downsampling.
Retraining: driftanfällige Modelle wöchentlich, Basismodelle monatlich. Erklärbarkeit durch SHAP/Feature‑Importance.
Quellen: IT‑Schulungen, KMUit.
Schritt‑für‑Schritt Roadmap: AIOps für KMU einführen
Ein realistischer Zeitraum: 6–9 Monate von null zu einem produktiven, messbaren System.
Phase 0 – Vorbereitung (1–2 Wochen)
Workshop mit IT‑Leitung, Entwicklung, Security und Business‑Owner. Deliverables: Projekt‑Charter, CMDB‑Export, Dateninventar.
Referenz: Blog Nowak.
Phase 1 – Bestandsaufnahme & Priorisierung (2–3 Wochen)
Prüfe Logs/Metriken/Traces (≥90 Tage), identifiziere Top‑10 Incident‑Typen, priorisiere Pilot‑Services nach Impact vs. Effort.
Quellen: IT‑Schulungen, Nowak.
Phase 2 – Pilot Setup (4–8 Wochen)
Datenquellen anschließen, erste Modelle in Staging deployen, Event‑Korrelation aktivieren, ITSM‑Konnektoren einrichten. Pilot‑Messung 2–4 Wochen. Erfolgskriterium: >30 % MTTR‑Verbesserung.
Phase 3 – Incident Automatisierung Roll‑out (4–6 Wochen)
Regelbasierte Playbooks implementieren, Dry‑Run und Shadow‑Mode testen, Orchestrierungsengine anbinden.
Quellen: IT‑Schulungen, OpenText.
Phase 4 – Auto‑Remediation & Skalierung (6–12 Wochen)
Schrittweise Aktivierung sicherer, idempotenter Aktionen, Canary‑Rollouts, automatisches Rollback, Governance‑Board einrichten.
Phase 5 – Betrieb & kontinuierliche Verbesserung (laufend)
Wöchentliche KPI‑Reviews, Modell‑Retraining bei Drift, Playbook‑Optimierung und kulturelle Begleitung im Team.
Pilot‑Checkliste: Was du vor dem Start prüfen musst
Diese Checkliste kannst du in deinen Workshop mitnehmen:
- Logs, Metriken, Traces mit ≥ 90 Tagen Historik (IT‑Schulungen).
- CMDB‑Export / Service‑Map vorhanden.
- Strukturierte Tags (Service, Environment, Host) gesetzt.
- SLA, MTTR, MTTD Ziele definiert; Pilot‑Services ausgewählt.
- Top‑3 Incident‑Typen identifiziert und auf Auto‑Remediation‑Tauglichkeit geprüft.
- RBAC, Audit‑Logging und Approval‑Gates konfiguriert (OpenText).
- Dry‑Run und Shadow‑Mode für jedes Playbook geplant.
Praxis‑Checkliste für den Produktionsbetrieb
- Produktive Log‑ und Metrikstreams stabil, Retention und Backups vorhanden.
- Alert‑Suppression für Wartungsfenster.
- Unveränderliche Audit‑Logs, RBAC, Approval‑Workflows, Credentials im Vault (IT‑Sicherheit für KMU).
- Observability der Automatisierung: Erfolgsrate, mittlere Remediation‑Zeit, Rollbacks.
Konkrete Playbooks: So sehen echte Automatisierungen aus
Playbooks sind das Herz der Incident Automatisierung. Drei typische Beispiele:
Playbook A – Netzwerk‑Latenz
Trigger: anhaltende Latenz + Paketverlust. Schritte:
- Agent‑Logs sammeln.
- Netzwerk‑Agent neu starten (idempotent).
- NOC benachrichtigen und Ticket erstellen, falls Neustart nicht hilft.
- Eskalation nach 15 Minuten.
Sicherheit: Dry‑Run und Limitierung der Neustarts.
Quelle: IT‑Schulungen.
Playbook B – Service CPU‑Spike
Trigger: CPU >85 % und steigende Fehlerrate. Schritte:
- Neue Replicas hochfahren (Kubernetes HPA).
- Traces & Logs sammeln.
- Ticket mit Kontext erstellen.
- Health‑Checks nach Skalierung ausführen.
Sicherheit: Canary Scaling, automatisches Rollback. Quelle: OpenText.
Playbook C – Speicher‑Auslastung
Trigger: Festplattenauslastung >85 % für >24 h. Schritte:
- Cleanup temporärer Dateien.
- Quota‑Warnung an Service‑Owner.
- Eskalation, wenn nicht gesunken.
Quelle: IT‑Schulungen.
Risiken, Fallstricke und wie du sie vermeidest
AIOps ist kein Selbstläufer. Häufige Fehler und Lösungen:
- Zu frühe Auto‑Remediation: immer Dry‑Run → Shadow → Produktion mit Approval Gates.
- Schlechte Datenqualität: Data‑Quality‑Checks, strukturierte Tags und 90 Tage Retention erzwingen.
- Feature Creep: Priorisierung, Pilot‑ROI messen, schrittweise Ausweitung.
Quellen: IT‑Schulungen, Mittelstandswiki, Trendskout.
Sicherheit, Compliance und Governance
Access Control: Least Privilege, Secrets im Vault (z. B. HashiCorp Vault, Azure Key Vault).
Audit & Forensik: ausführende Accounts, Timestamp, Befehlsprotokolle.
Datenschutz: keine personenbezogenen Daten in Trainingslogs; Anonymisierung notwendig.
Governance Board: jedes Playbook muss freigegeben werden; quartalsweise Reviews.
Quellen: OpenText, IT‑Schulungen.
Rollen und Change Management: Menschen mitnehmen
Technik allein reicht nicht. Definiere klare Rollen und bilde das Team:
- AIOps‑Owner: KPI‑Tracking und Priorisierung.
- SRE/Operations: Runbooks, erste Anlaufstelle.
- Entwicklung: Fixes und Service‑Wissen.
- Security: RBAC und Remediation‑Freigabe.
- Business‑Owner: Sponsoring und ROI‑Sichtbarkeit.
Training: Tools lesen → KI‑Ergebnisse interpretieren. Misstrauen abbauen durch Transparenz und Override‑Button.
Quellen: Mittelstandswiki, IT‑Schulungen.
Tools und Anbieter auswählen: Worauf du achten musst
Vendor‑Checkliste:
- Unterstützt die Plattform KI‑Monitoring und Event‑Korrelation out‑of‑the‑box?
- APIs, Webhooks, SDKs für Incident‑Automatisierung vorhanden?
- Auto‑Remediation mit RBAC, Approval Gates, Audit‑Logging integriert?
- TCO, Managed Service Optionen, Skalierbarkeit und Support‑SLA?
- Verschlüsselung, Secrets‑Manager Integration, Compliance‑Standards?
Proof Points: Referenzkunden aus dem Mittelstand, konkrete Case Studies.
Quellen: IT‑Schulungen, OpenText, HPE, Trendskout.
Erfolgsbeispiele: Was KMU mit AIOps erreicht haben
E‑Commerce‑Mittelstand: MTTR um 60 % gesenkt nach Einführung von KI‑Monitoring und Event‑Korrelation (HPE‑Bericht).
Produktionsbetrieb: 40 % der Routine‑Incidents automatisiert, Team konnte strategische Projekte vorantreiben (Mittelstandswiki).
Dein 30‑Minuten‑Mini‑Audit: Bist du bereit für AIOps?
Ein schnelles Audit liefert innerhalb von 30 Minuten eine erste Einschätzung.
- 0–5 Min: Stakeholder prüfen (IT‑Leiter, Business‑Owner, Security).
- 5–15 Min: Daten‑Check (Logs, Metriken, ≥90 Tage, strukturierte Tags).
- 15–25 Min: Top‑5 Incidents der letzten 90 Tage auflisten.
- 25–30 Min: Drei Ja/Nein‑Fragen: Daten bereit? Pilot‑Service vorhanden? Security/Governance vorhanden? ≥2x Ja → Piloten‑Start möglich.
Nächste Schritte: Pilot‑Charter erstellen, Betriebsmodell wählen (intern / SaaS / Managed Service), Kick‑off‑Workshop planen.
Quellen: Nowak, OpenText, Trendskout.
Fazit: AIOps für KMU – jetzt anfangen, nicht abwarten
AIOps ist kein Luxus: Schon ein Pilot mit 1–2 Services kann MTTR um 30 % oder mehr reduzieren.
Wichtige Erfolgsfaktoren: KI‑Monitoring, Event‑Korrelation, Incident‑Automatisierung und Auto‑Remediation im Zusammenspiel — plus Menschen, Sicherheit und Governance.
Takeaways in Kürze:
- Pragmatisch starten → Pilot messen → skalieren.
- Vier Komponenten müssen zusammenspielen.
- Transparenz und Override‑Möglichkeit für das Team sind unverzichtbar.
- Starte heute mit dem 30‑Minuten‑Mini‑Audit.
Quellen & weiterführende Lektüre:
HPE AIOps‑Blog,
IT‑Schulungen,
Blog Nowak.
FAQ
F1: Wie viel Datenhistorie brauche ich für AIOps‑Modelle?
In der Regel mindestens 90 Tage historische Logs und Metriken, idealerweise mit einer Auflösung von 1–5 Minuten und strukturierten Tags.
F2: Ist Auto‑Remediation sicher für die Produktion?
Ja — wenn Sicherheitsmechanismen wie Dry‑Run, Approval‑Gates, idempotente Aktionen, automatisches Rollback, Audit‑Logging und RBAC implementiert sind.
F3: Welche KPIs sollte ich im Pilot messen?
MTTR, MTTD, Auto‑Remediation‑Rate, Alert‑Reduktion (%), False‑Positive‑Rate und eingesparte FTE‑Stunden.
F4: Kann ein kleines IT‑Team AIOps selbst betreiben?
Ja — entweder intern mit ausreichender Expertise, per SaaS für schnelleren Time‑to‑Value oder als Managed Service, wenn das Team entlastet werden soll.
F5: Wo finde ich Praxisbeispiele und Referenzen?
Startpunkte: HPE AIOps‑Blog, Mittelstandswiki, OpenText.